
Feasibility study of long-form question answering
Long-form answers can be context-dependent and need to incorporate information from multiple sources to form a satisfying answer. In a way, long-form question answering (LFQA) is analogous to producing short essay answers to questions. My master’s thesis aimed to answer how feasible it is to bring LFQA to production and what its successful use requires.
Neural question-answering has undoubtedly seen tremendous advances with neural language models such as BERT and GPT setting state-of-the-art results on various QA-datasets, which require the models to produce answers to short questions or extract answers spans from documents. Still, the success of these models is not guaranteed to transfer to real-world tasks as often, questions we ask are best answered by long-form answers, which means that the answers produced by the neural model have to span one or more paragraphs in length.
Moreover, these long-form answers can be highly context-dependent and need to incorporate information from multiple sources to form a satisfying answer. In a way, long-form question answering is analogous to producing short essay answers to questions you might see in university or high-school exams.
To this end, my master’s thesis aimed to answer how feasible it is to bring LFQA to production and what challenges lay before its successful use. To accomplish this, I surveyed the field of neural question-answering identifying methods and challenges we face when building LFQA models. Then, using this knowledge, I built LFQA models, which are used to answer questions on a challenging QA task requiring deep domain knowledge of the Ubuntu operating system. The thesis was done as part of the ongoing Oxilate research project.
Challenges in LFQA
Before building an LFQA model, we need to be conscious of the limitations of current methods. The performance of current neural models is largely the result of the increasing computational capacity. As decreasing the model’s error rate by half requires roughly an exponential amount of more computing, we could well outpace available computational resources before acceptable performance is achieved [1]. Alternatively, we could be waiting for quite a few years before such compute is available.
Moreover, the current level of understanding the neural language models possess is quite limited, with the models having problems with logical consistency and faithfulness to input. Slightly differently worded questions can lead to entirely different answers. As a result, you cannot often bring a model to production, which is prone to falsehoods, limiting the application areas substantially.
Building an LFQA model
Building a neural question answering model is quite simple these days, with abundant data available to be mined from the internet and neural language models available in libraries such as Hugginface Transformers [2].
To build the dataset, we first extracted question-answer pairs from the Askubuntu dataset, which is part of the larger Stack Exchange data dump [3]. This resulted in over a hundred thousand QA pairs we could use to train our models on. Additionally, we data mined supporting documentation from Google search results using the extracted questions to find web pages, which might contain helpful information to help the model answer the question.
We tried to make sure that answers could not be read straight from any web page we data mined so that the model has to display a deeper understanding of the subject matter to form an answer with the help of the supporting documentation. This is analogous to an open book exam, where the book acts as a supporting information source but where you cannot obviously copy a page from the book to form an answer.
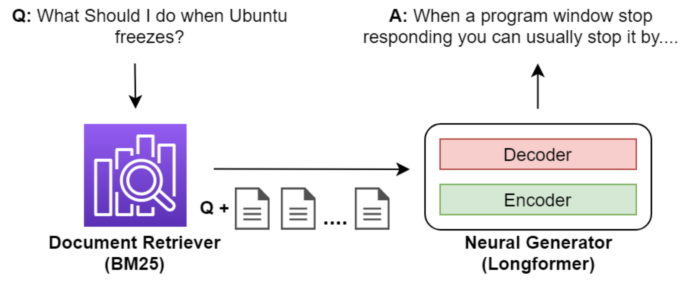
For the model architecture, we largely followed the example set in DrQA [4], with minor modifications. First, our model consists of a retriever component, which indexes the supporting documentation and then retrieves it for the given question. Then the question and retrieved documentation is fed into a neural generator model, which produces a free-form answer to the question.
For the neural generator model, we used the Longformer: The Long-Document Transformer [5], which is a neural Transformer much like BERT, with the distinction that it can take as model inputs and outputs much longer texts than BERT. This means that the model can take as input a much larger amount of supporting documentation, which in theory should lead to better answers.
The complete model architecture can be seen in the underlying figure.
Evaluating the models and results
Using commonly used automatic evaluation metrics, evaluating long-form questions can lead to misleading results as long-form answers can vary significantly in length and text contents. This is because automatic evaluation metrics can have length biases and do not consider enough of the variability of text between the reference answer and the answer produced by the neural model. This means that we have to rely on human evaluation to best evaluate long-form answers. To this end, we asked a group of ten human evaluators to rate answers based on factors such as fluency, correctness, and preference over the reference answer.
Overall, the human evaluation results showed that although neurally generated are very fluent in their language use and are often indistinguishable from reference answers, the answers were rated relatively low regarding the correctness of the answer and preference over the reference answer. Moreover, the neural models used did not benefit significantly from the supporting documentation, suggesting that taking into account large amounts of input context remains a difficult task for neural language models.
Considering the small number of resources we had for the project, we were quite satisfied with our results. Although neurally generating long-form answers often remains a task, which there is a lot of room improvement before it can be put into production, the simpler task of predicting answer spans from retrieved documents can be productionized much more easily as it does not suffer from many of the challenges we face when neurally generating answers. A good example of this kind of extractive long-form question answering can be found with Longformer on the NLQuAD-dataset [6].
For more information on building neural question answering systems: How to Build an Open-Domain Question Answering System?
[1] https://arxiv.org/abs/2007.05558[2] https://github.com/huggingface/transformers
[3] https://archive.org/details/stackexchange
[4] https://github.com/facebookresearch/DrQA
[5] https://github.com/allenai/longformer
[6] https://aclanthology.org/2021.eacl-main.106/
Simo Antikainen
Software Designer