
Älä anna datan valua hukkaan – kuinka tunnistaa ja hyödyntää poikkeamia?
Nykyaikaiset teolliset laitteet ja prosessit tuottavat dataa ympäri vuorokauden, joka sekunti. Suuressa määrässä dataa esiintyy myös poikkeamia. Miten tällaisia poikkeamia voidaan tunnistaa ja hyödyntää?
Jatkuva datavirta sisältää arvokasta tietoa esimerkiksi laitteiden toiminnasta ja muista kriittisistä prosessin osa-alueista. Mutta miten tämä usein massiivinen ja monimuotoinen datamäärä saadaan muutettua konkreettiseksi hyödyksi?
Yksinkertaisista tilastollisista menetelmistä syvällisiin menetelmiin
Yksinkertaiset tilastolliset menetelmät, kuten keskiarvo, mediaani ja hajonta, voivat antaa ensimmäisen käsityksen datan rakenteesta ja mahdollisista poikkeavuuksista. Myös visualisointi on tehokas työkalu: kaaviot ja kuvaajat voivat paljastaa trendejä ja poikkeamia, jotka jäävät helposti huomaamatta raakadatan taulukkomuodossa.
Koneoppiminen tarjoaa työkaluja ja menetelmiä, joilla voidaan löytää rakenteita, malleja ja oivalluksia datasta, joka muuten olisi liian laaja ja monimutkainen ihmisen analysoitavaksi. Koneoppimismallit voivat oppia tunnistamaan datan normaaleja käyttäytymismalleja ja ennakoida mahdollisia poikkeavuuksia, jotka voivat kieliä esimerkiksi laitteiston vikaantumisesta.
Outlier Detection – datan poikkeamien tunnistus
Outlier detectionilla (poikkeavuuksien/anomalioiden tunnistaminen) tarkoitetaan menetelmiä, joilla pyritään tunnistamaan poikkeavat havainnot datajoukosta. Nämä poikkeavat arvot, eli ”outlierit”, ovat merkittävästi erilaisia verrattuna muihin saman datan havaintoihin.
Poikkeamat voivat johtua monenlaisista syistä. Teollisessa ympäristössä poikkeavia havaintoja voi syntyä esimerkiksi mittausvirheistä, koneen tai sen käyttäjän poikkeavasta toiminnasta, tai ne voivat olla merkkejä jostakin uudesta harvinaisesta ilmiöstä. Toisaalta outlierien havainnointia voi hyödyntää myös datan esiprosessoinnissa, sillä outlierit voivat aiheuttaa vinoumia datan analysoinnissa. Poikkeamien poistaminen voi olla esimerkiksi tarpeen ennen koneoppimismallin koulutusta.
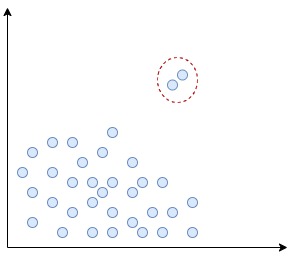
Poikkeamien tunnistamiseen on olemassa lukuisia menetelmiä, jotka ulottuvat tilastollisista menetelmistä monimutkaisiin neuroverkkoihin perustuviin menetelmiin. Poikkeamat voivat olla datajoukon mielenkiintoisimpia pisteitä tai vain häiriötä riippuen poikkeamien syntymekanismista ja datan käyttötarkoituksesta. Tämän takia poikkeamien juurisyiden selvittäminen on olennaista raakadatan ymmärtämisen kannalta.
Hyödynnä dataa ja ennakoi
Poikkeamien syyt voivat olla moninaiset, ja ne voivat sisältää piilossa olevia signaaleja, jotka kertovat laitteiden vikaantumisesta, yllättävistä prosessimuutoksista tai muista kriittisistä häiriöistä. Poikkeamien tunnistamisen avulla voidaan löytää syitä ja olosuhteita, joita havaitsemalla voidaan ryhtyä korjaaviin toimenpiteisiin. Tällöin voidaan välttää esimerkiksi odottamattomat laiterikot, tuotantokatkokset ja niistä aiheutuvat suuret taloudelliset menetykset.
Datan tehokas hyödyntäminen poikkeamien tunnistuksessa ja ennakoinnissa on kriittistä teollisten prosessien ja laitteiden hallinnassa. Se ei ainoastaan vähennä odottamattomia kustannuksia, vaan myös mahdollistaa toiminnan jatkuvan kehityksen ja tehokkuuden parantamisen. Teollisessa ympäristössä data ei ole pelkkää numeerista tietoa, vaan arvokas resurssi, joka tarjoaa syvällistä ymmärrystä ja kilpailuetua niille, jotka osaavat hyödyntää sitä oikein.

Jere Toivonen
Ohjelmistosuunnittelija

Ida Pellinen
Markkinointi- ja viestintäasiantuntija